Self-supervised Learning for Tabular Datasets
Self-supervised learning aims to learn latent representations for unlabeled datasets. It has shown to be an effective representation learning method; even outperforming supervised representation learning in some settings, such as Transfer Learning. In the previous blog posts, I covered self-supervised learning and briefly explained various collapsing solutions. Here, I am going to write about the recent works on targeting to unleash the power of self-supervised learning for tabular datasets.
The Problem With Tabular Datasets
As I explained here, self-supervised learning can be roughly categorized into two main categories: pre-text task learning and contrastive learning (although you can see contrastive learning as a special case for pre-text task learning where the task is to learn a feature space such that map similar samples are located close to each other). Pre-text task learning defines a pre-text task, such as predicting the rotation degree of a rotated image. Contrastive learning can be defined using the notion of positive and negative pairs. For each sample x, we first create its positive pair by augmenting x, and then push the network to map x and its positive pair close to each other. To avoid collapsing solutions, we also push the network to map x far away from its negative pairs. We define negative pairs of x as all other samples plus their positive pairs.
The problem with the current self-supervised approaches is that they are carefully curated for special data types. For example, pre-text task learning methods are defined based on unique characteristics of data, e.g., solving a jigsaw puzzle in computer vision or token masking in natural language processing. This problem also holds for contrastive learning, where augmentation methods are defined to create a different yet semantically similar positive pair. This is the reason why there has been a surge in proposing new self-supervised representation learning methods for tabular datasets. In this blog post, I am going to briefly introduce the main idea of three recent such papers: VIME (NeurIPS 2020), SubTab (NeurIPS 2021), and SCARF (ICLR 2022).
VIME
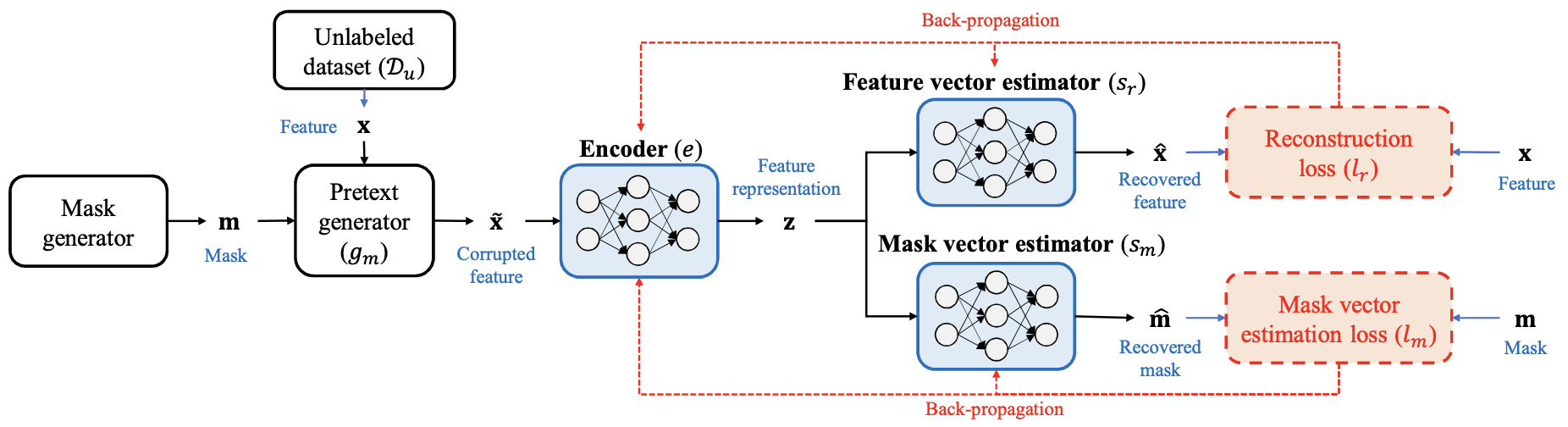
We all love auto-encoders, and in particular denoising auto-encoders! In denoising auto-encoders we randomly corrupt the input and train the auto-encoder to compute the reconstruction loss using the original uncorrupted data as the target, forcing our auto-encoder to learn the correlation between features and denoise our input. In VIME authors take this idea one step further and add one extra task to the network: to predict the binary mask of corrupted features.
As you can see in the picture above, VIME creates a mask m for each sample x, and uses this mask to choose which features of x to corrupt. After corruption, it feeds the corrupted x into the network with two prediction heads. One head is in charge of predicting m, and the other head’s job is to predict the original uncorrupted x.
SubTab
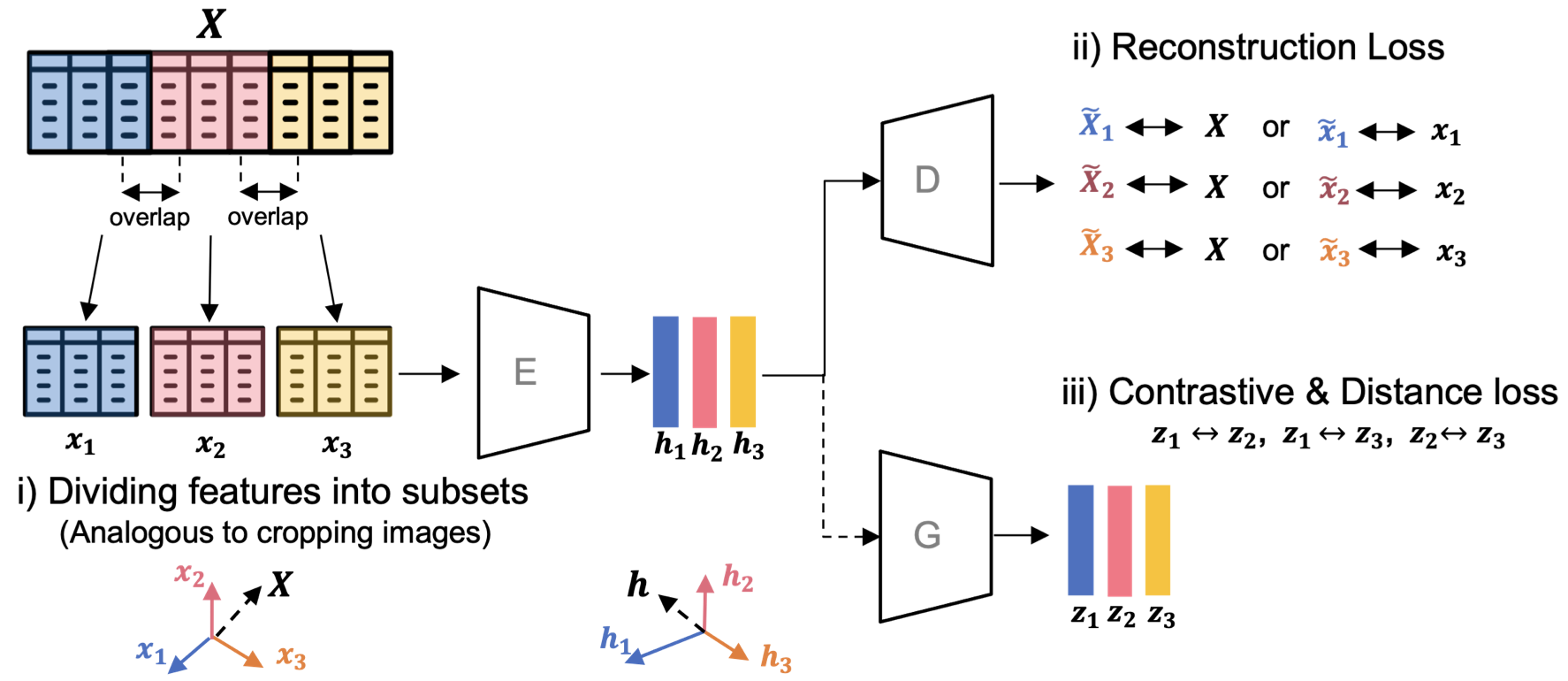
SubTab is another self-supervised learning method based on pre-text task learning. The novel idea in SubTab is it trains the neural network using subsets of features, instead of all the features. As it is demonstrated in the picture above, SubTab divides each input x into multiple overlapping subsets, x1, x2, …, xn. These subsets are used to train the network with three different losses: reconstruction loss, contrastive loss, and distance loss.
During inference, for each test sample x, SubTab aggregates representations of x1, x2, …, and xn by taking their average. This average acts as the x’s latent representation which we can further feed to the prediction head.
SCARF
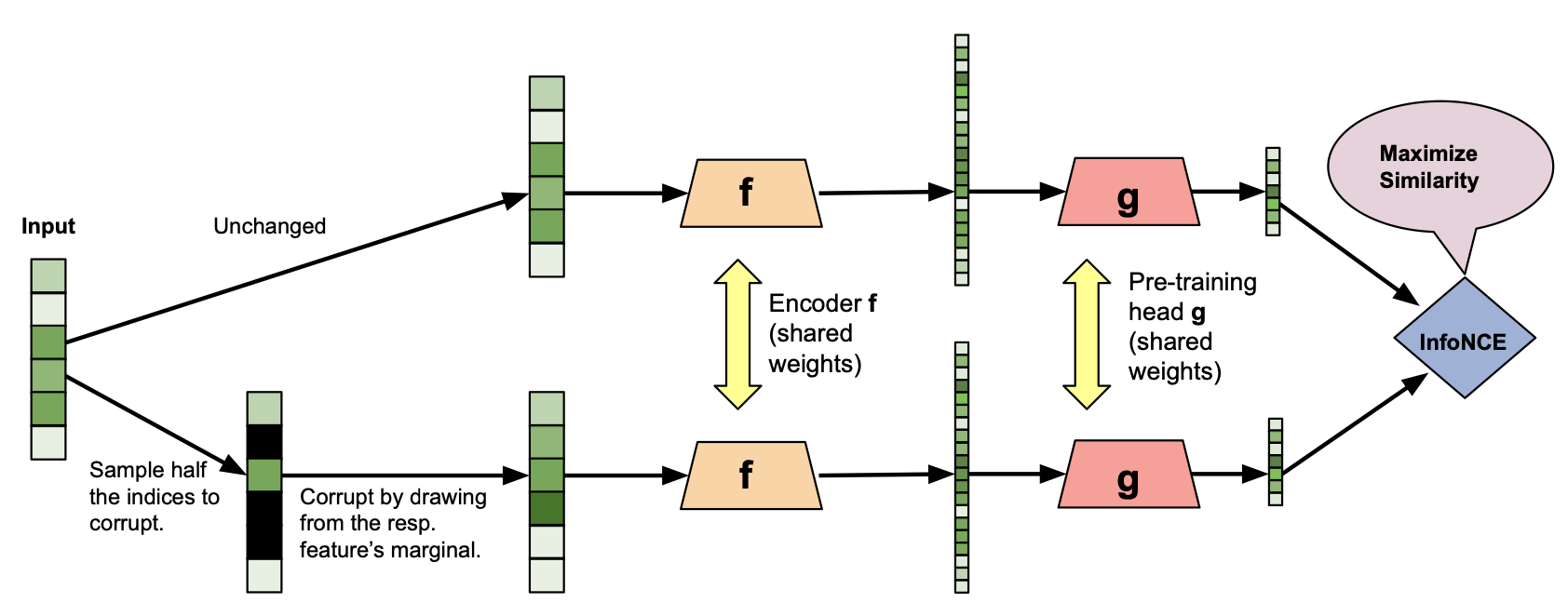
SCARF is a contrastive learning method for tabular datasets. SCARF proposes a method to augment tabular data and create positive samples, which could be later used in contrastive learning. The augmentations method that SCARF proposes is as follows: For each sample x, we randomly choose some of its features. Then we replace the value of each chosen feature with the corresponding empirical marginal distribution for that feature. For example, let’s say we want to replace the value of the second feature in x. What we do is we randomly select another sample from our dataset and copy its second feature.
In this article, I pointed out the problem of self-supervision on tabular datasets and introduced the core idea of three self-supervised representation learning methods tailored for tabular datasets. This is a fairly new research topic, which has been getting some attention recently. In fact, there is going to be a workshop on the topic of “Representation Learning for Tabular Data” in this year’s NeurIPS for the first time. Here is the link to the workshop and here is the list of all the accepted papers.
Comments powered by Disqus.